JAVA后端全套
JavaSE
尚硅谷Java基础

第一章 java基础
1.1 编程语言介绍
第一代语言 机器语言:指令以二进制代码形式存在。
第二代语言 汇编语言:使用助记符表示一条机器指令。
常用语言对比:
- C语言:执行效率比较高,一般用来做底层驱动或者操作系统。
- C++:游戏内核,应用程序。
- C#:微软、支持的平台是windows,基于.netframework的。
- Java:世界第一,toibe排行榜。
- Python:脚本语言,灵活性极高。
- html:静态网页,网站
- CSS:美化网页
- JS:动态网页
- go语言:谷歌开发
- Sql:数据库,数据是软件的根本
语言类型:
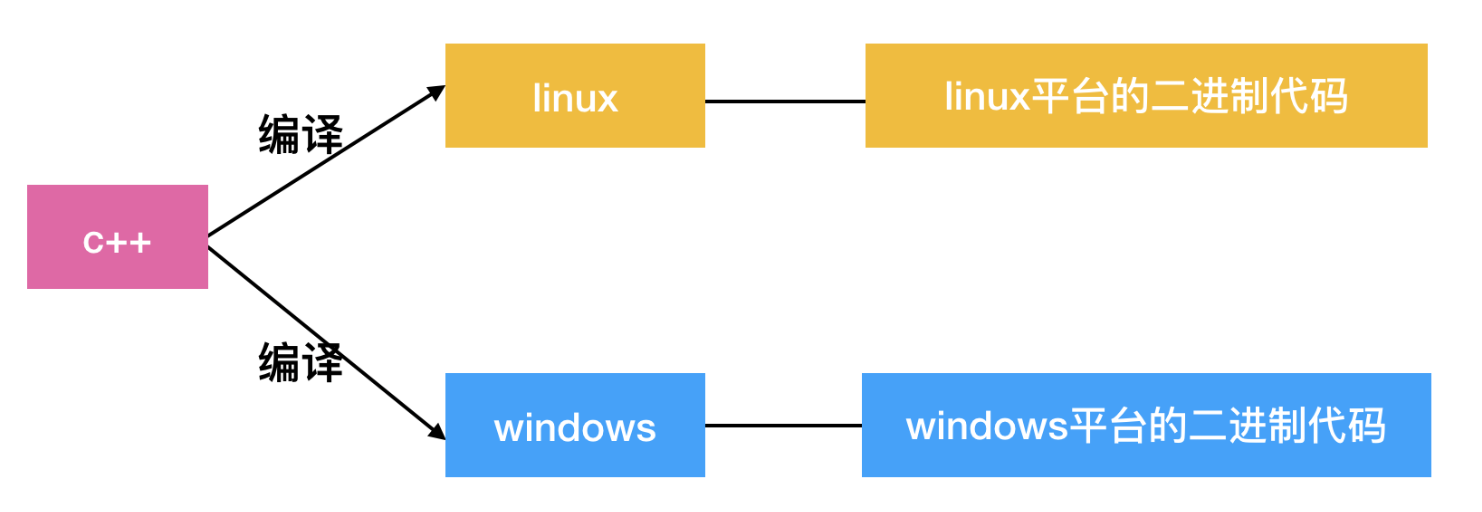
编译型:一次编译,到处运行。
执行效率较高,跨平台比较差
解释型:一行一行解释,执行。
执行效率较低,跨平台性较好。
混合型,譬如Java。
1.2 Java简介
Java是一门程序开发语言. 1991年由sun公司的James Gosling和他的团队一起开发了一个叫Oak的语言. 在1995年更名为Java. 一直沿用至今。
1991年 Green项目,开发语言最初命名为Oak (橡树)
1994年,开发组意识到Oak 非常适合于互联网 1996年,发布JDK 1.0,约8.3万个网页应用Java技术来制作
1997年,发布JDK 1.1,JavaOne会议召开,创当时全球同类会议规模之最 1998年,发布JDK 1.2,同年发布企业平台J2EE
1999年,Java分成J2SE、J2EE和J2ME,JSP/Servlet技术诞生
2004年,发布里程碑式版本:JDK 1.5,为突出此版本的重要性,更名为JDK 5.0
2005年,J2SE -> JavaSE,J2EE -> JavaEE,J2ME -> JavaME
2009年,Oracle公司收购SUN,交易价格74亿美元
2011年,发布JDK 7.0
2014年,发布JDK 8.0,是继JDK 5.0以来变化最大的版本
2017年,发布JDK 9.0,最大限度实现模块化
2018年3月,发布JDK 10.0,版本号也称为18.3
2018年9月,发布JDK 11.0,版本号也称为18.9
特点:针对C++简化了很多

诞生:java之父James Gosling团队在开发”Green”项目时,发现C缺少垃圾回收系统,还有可移植的安 全性、分布程序设计和多线程功能。最后,他们想要一种易于移植到各种设备上的平台。 Java确实是从C语言和C++语言继承了许多成份,甚至可以将Java看 成是类C语言发展和衍生的产物。比如Java语言的变量声明,操作符 形式,参数传递,流程控制等方面和C语言、C++语言完全相同。但同 时,Java是一个纯粹的面向对象的程序设计语言,它继承了C++语言 面向对象技术的核心。Java舍弃了C语言中容易引起错误的指针(以 引用取代)、运算符重载(operator overloading)、多重继承 (以接口取代)等特性,增加了垃圾回收器功能用于回收不再被引用 的对象所占据的内存空间。JDK1.5又引入了泛型编程(Generic Programming)、类型安全的枚举、不定长参数和自动装/拆箱。
Java特性:
- Java语言是易学的。Java语言的语法与C语言和C++语言很接近,使得大多数程序员 很容易学习和使用Java。
- Java语言是强制面向对象的。Java语言提供类、接口和继承等原语,为了简单起见, 只支持类之间的单继承,但支持接口之间的多继承,并支持类与接口之间的实现机制 (关键字为implements)。
- Java语言是分布式的。Java语言支持Internet应用的开发,在基本的Java应用编 程接口中有一个网络应用编程接口(java net),它提供了用于网络应用编程的类 库,包括URL、URLConnection、Socket、ServerSocket等。Java的RMI(远程 方法激活)机制也是开发分布式应用的重要手段。
- Java语言是健壮的。Java的强类型机制、异常处理、垃圾的自动收集等是Java程序 健壮性的重要保证。对指针的丢弃是Java的明智选择。
- Java语言是安全的。Java通常被用在网络环境中,为此,Java提供了一个安全机 制以防恶意代码的攻击。如:安全防范机制(类ClassLoader),如分配不同的名字空间以防替代本地的同名类、字节代码检查。
- Java语言是体系结构中立的。Java程序(后缀为java的文件)在Java平台上被 编译为体系结构中立的字节码格式(后缀为class的文件),然后可以在实现这个 Java平台的任何系统中运行。
- Java语言是解释型的。如前所述,Java程序在Java平台上被编译为字节码格式, 然后可以在实现这个Java平台的任何系统的解释器中运行。
- Java是性能略高的。与那些解释型的高级脚本语言相比,Java的性能还是较优的。
- Java语言是原生支持多线程的。在Java语言中,线程是一种特殊的对象,它必须 由Thread类或其子(孙)类来创建。
java语言特点:
特点一:面向对象
- 两个基本概念:类、对象
- 三大特性:封装、继承、多态
特点二:健壮性
- 吸收了C/C++语言的优点,但去掉了其影响程序健壮性的部分(如指针、内存的申请与 释放等),提供了一个相对安全的内存管理和访问机制
特点三:跨平台性
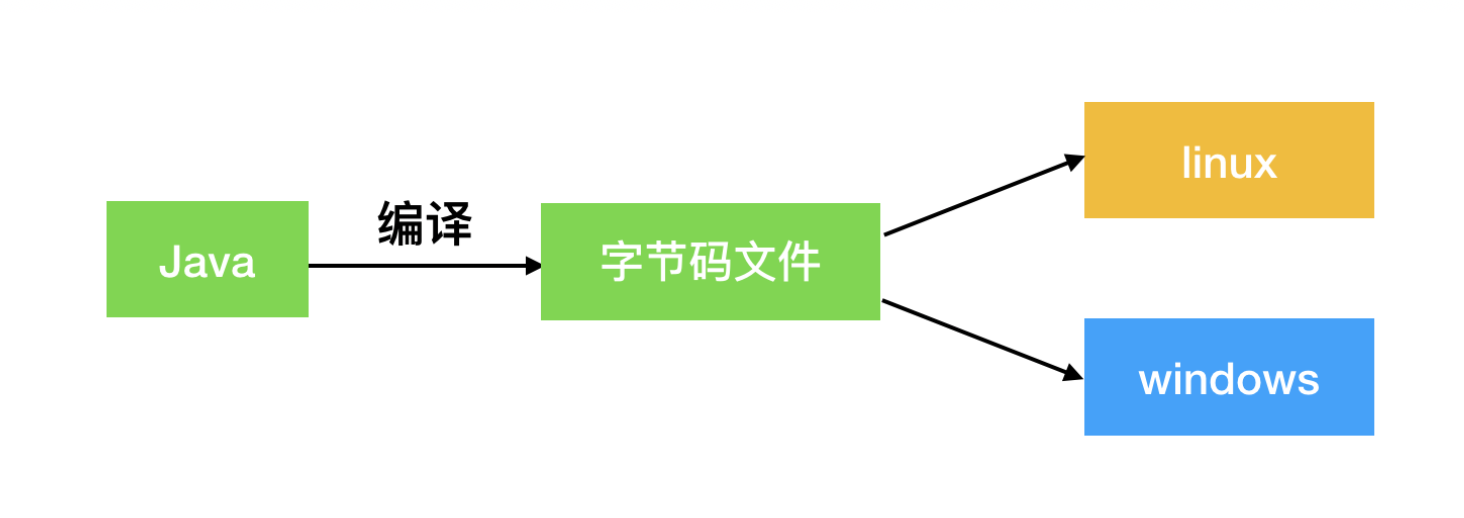
跨平台性:通过Java语言编写的应用程序在不同的系统平台上都可以运行。“Write once , Run Anywhere”
原理:只要在需要运行 java 应用程序的操作系统上,先安装一个Java虚拟机 (JVM Java Virtual Machine) 即可。由JVM来负责Java程序在该系统中的运行。
因为有了JVM,同一个Java 程序在三个不同的操作系统中都可以执行。这 样就实现了Java 程序的跨平台性。

Java的两个核心机制:
Java虚拟机 (Java Virtal Machine)
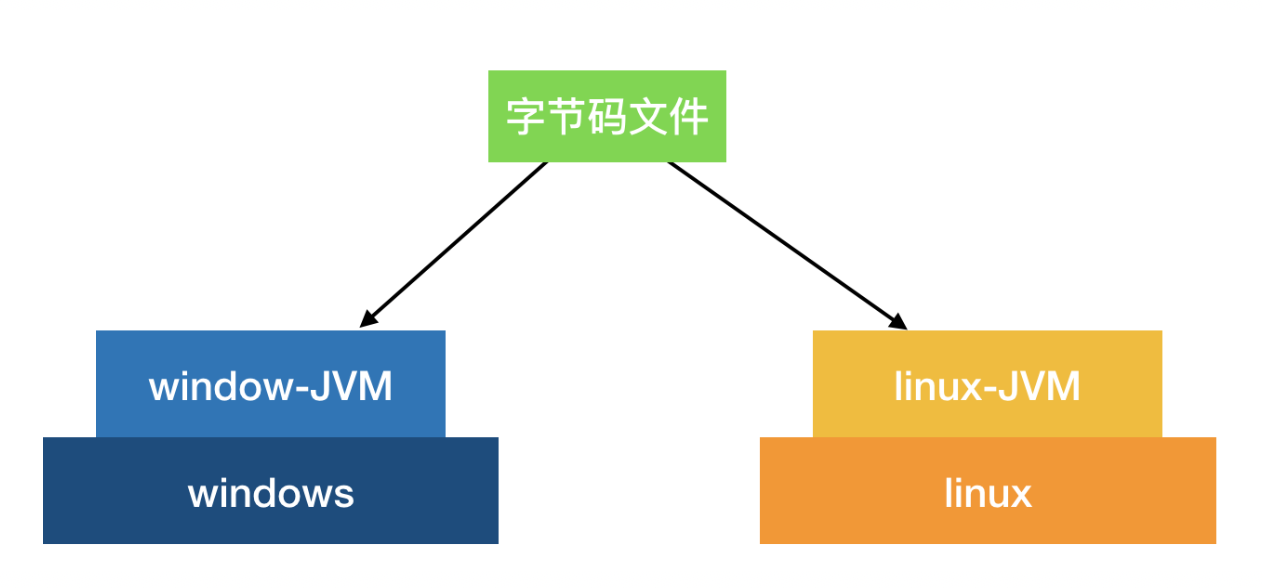
JVM是一个虚拟的计算机,具有指令集并使用不同的存储区域。负责执行指令,管理数据、内存、寄存器。
对于不同的平台,有不同的虚拟机。
只有某平台提供了对应的java虚拟机,java程序才可在此平台运行。
Java虚拟机机制屏蔽了底层运行平台的差别,实现了“一次编译,到处运行”。

垃圾收集机制 (Garbage Collection)
不再使用的内存空间应回收—— 垃圾回收。
- 在C/C++等语言中,由程序员负责回收无用内存。
- Java 语言消除了程序员回收无用内存空间的责任:它提供一种系统级线程跟踪存储空 间的分配情况。并在JVM空闲时,检查并释放那些可被释放的存储空间。
垃圾回收在Java程序运行过程中自动进行,程序员无法精确控制和干预。
Java程序还会出现内存泄漏和内存溢出问题吗?会!
Java相关概念:
- JVM(Java Virtual Machine):Java虚拟机,用来模拟统一的硬件平台环境,供Java程序运行的一个软件。
- JRE(Java Runtime Environment):Java运行时环境,里面包含了JVM和一些Java运行时的类库。
- JDK(Java Development Kit):Java开发工具包、包含JRE和Java开发工具包。

常用DOS命令:

1.3 第一个Java程序
1 | |
public class Hello:这一行表示创建一个类,类是Java程序运行的最小单元,必须要有类。
public static void main(String[] args):Java程序入口,一切从这里开始执行。
System.out.println("Hello world!!!"):让程序打印一句话,内容是引号中的内容。
注意:Java程序严格区分大小写,写错一个字母都不行。
1.4 Java注释
一、单行注释
1 | |
二、多行注释
1 | |
三、文档注释
1 | |
注释场景:
- 核心的解决方案
- 比较难懂的业务逻辑
- 记录代码存在经历
1.6 变量
变量: 可以发生改变的量. 程序运行过程中产生的中间值。供后面的程序使用。
java中的变量:数据类型 变量名 = 值;
int 类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class type {
public static void main(String[] args) {
int a = 20, b = 20;
int c = a + b;
System.out.println(a);
System.out.println(b);
System.out.println("a + b = " + c);
int d = a - b;
System.out.println("a - b = " + d);
int e = a * b;
System.out.println("a * b = " + e);
int f = a / b;
System.out.println("a / b = " + f);
}
}double型:小数,计算结果一定也是小数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class type {
public static void main(String[] args) {
double a = 20, b = 20;
double c = a + b;
System.out.println(a);
System.out.println(b);
System.out.println("a + b = " + c);
double d = a - b;
System.out.println("a - b = " + d);
double e = a * b;
System.out.println("a * b = " + e);
double f = a / b;
System.out.println("a / b = " + f);
}
}String字符串:注意(String)的S必须大写。
1
2
3
4
5
6
7
8
9
10public class type {
public static void main(String[] args) {
String s1 = "为什么不在自信一点?";
String s2 = "你快变成你自己最讨厌的样子了,zjl,你知道吗?";
String s3 = "为什么你总是因为害怕失败而不敢去尝试?";
String s4 = s3 + "你应该知道因为这样你失去了多少东西";
System.out.println(s4);
}
}bollean布尔值:非真即假。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class type {
public static void main(String[] args) {
boolean a = true;
boolean b = false;
System.out.println(a);
System.out.println(b);
boolean c = 1 > 2;
boolean d = 2 > 1;
System.out.println(c);
int e = 10;
System.out.println(e == 10);
System.out.println(e != 10);
}
}
中文乱码:UTF-8 –> GBK
1.7 用户输入
1 | |
注意:不出意外,会自动跳过录入姓名项,因为和C语言类似,我们没有去清除Enter,会导致后续录入字符串读入Enter导致直接结束录入,要看效果,把前面的两个删除即可.
1.8 If语句
1 | |
1.9 while循环(略)
1.10 作业
猜数字游戏
1 | |
1.11二进制转化(略)
1.12 编码
现代计算机编码类型:
- ASCII码:最开始编码,只支持英文,8比特。
- ANSI码:对ASCII的扩展,只是一套标准,不同的国家使用该标准对自己国家的文字进行编码。
- GBK:中国ANSI编码,起名GB码,后期扩展成GBK,GBK兼容ASCII,16比特。
- Unicode:由于各个国家的编码不相容,由国际标准化组织ISO和统一码联盟制作了Unicode,对各国文字进行统一编码,32比特。
- UTF-8:由于编入很多国家文字,占用内存很大,网络传输占用带宽,于是产生了UTF-8,是可变长度的Unicode,全称:Unicode Transformation Format。对于不同的文字信息,UTF的长度不同,英文8比特,欧洲文字16比特,中文24比特。
1.13 Java基础数据类型
- 基础数据类型:
- 整数
- byte:字节,1字节,范围-128~127
- short短整数:2字节,-32768~32767
- int整数:4字节
- long长整数:8字节
- 浮点数
- float:单精度浮点数,精度低。
- double:双精度浮点数,精度高。
- 字符
- char:字符类型,表示单个字符,2字节。
- 布尔
- boolean:布尔类型,两个取值(true,false)
- 整数
- 引用数据类型:除开基本数据类型以外,其他数据类型全是引用数据类型,最典型的:字符串String。
- 字符串可以执行加法运算,表示字符串拼接。
- 当出现非字符串和字符串进行相加的时候. 首先把非字符串自动转化成字符串然后再执行拼接操作。
- 转义字符:具有特定含义的字符串。
- \n:换行符
- \t:水平制表符
\':'\":\
1.14 基础数据类型之间的转化
一般是对数字进行转化,char和boolean类型一般不参与转化。
我们把数据类型进行排序, 按照能表示的数据量的范围进行排序:
- byte->short-> int ->long->float->double
- long排在float前面,因为整数是有数据量的范围的,而小数是没有的,
从小数据类型向大数据类型转化是直接转化的。
1 | |
大数据类型向小数据类型转化,需要强制类型转换。
1 | |
1.15 基本数据类型之间的运算
相同数据类型之间运算,得到的一定是这个数据类型。
- int = int +int
不同数据类型之间运算:首先把小的数据类型转化为大的数据类型·1,然后进行计算,得到的结果一定时大的数据类型。
- long = long + int
特殊的byte、short、char:执行算数运算时,首先会转化为int类型再进行计算,因为这样是安全的。
int = int + char
int = byte + byte
1
2
3
4
5
6
7public class type {
public static void main(String[] args) {
char a = 'A';
int b = 100;
System.out.println(a+b); // 10
}
}输出:165;证明是这样的。
相关报错:
1
2
3short a = 1;
short b = a + 1;
System.out.println(b);此时第2行代码一定会报错。
因为s1是short类型。而short类型计算的时候会自动转换成int进行计算。并且,所有的数字, 默认都可以看做是int类型, 默认的小数都可以看做是double类型,所以第二行计算的结果应该是int类型。把int类型的数据赋值给short类型的变量,一定会报错的,此处必须要进行强制类型转换。
1.16 基本运算符
算数运算符:+ - * /
复制运算符:
=
+=
-=
*=
/=
%=
比较运算符:> < >= <= != ==
结果一定是boolean类型。
如果是字符串比较,不能用
==,要用equals1
2
3
4
5
6
7
8
9
10
11
12
13public class type {
public static void main(String[] args) {
String str1 = "我是憨批";
String str2 = "我是憨批";
System.out.println(str1 == str2);
System.out.println(str1.equals(str2));
String str3 = new String("我是憨批");
String str4 = new String("我是憨批");
System.out.println(str3 == str4);
System.out.println(str3.equals(str4));
}
}输出:
1
2
3
4true
true
false
true逻辑运算符:
&:并且
|:或者
! :取反
&&:短路与
||:短路或
|, || 或者的含义, 左右两端同时为假,结果才能是假。
&, && 并且的含义. 左右两端同时为真,结果才能是真。
短路:再执行并/或运算时,如果式子的前面已经得到了结果,那么式子的后半段就不再继续进行运算了,效率较高。(与:有假就停,或:有真就停)。
一元运算
a++;
a–;
1.17 switch语句
switch变量必须是int或者String。
1 | |
注意:break一定不要忘记,如果没有及时跳出switch,会发生case穿透现象。
case穿透:如果有一个case匹配成功,则后面的case不会继续判断,而是直接执行后续的所有case成立语句。
1.18 for循环(略)
死循环:
1 | |
1.19 do……while循环
无限循环:
1 | |
注意不要忘记while后面的 ;
1.20 break和continue
break:停止当前循环,用于while/for/do……while循环
contiune:停止当前这次循环,跳至循环体代码末尾。(循环过程中,某些数据不需要处理时,可以使用它跳过。)
1 | |
1.21 数组
声明时需要给出数据类型。
1 | |
数组越界、数组遍历,略
1.22 数组算法
程序 = 算法 + 数据结构
质数:只能被1和自生整除的数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import java.util.Scanner;//导入Scanner包
public class type {
public static void main(String[] args) {
Scanner object = new Scanner(System.in);
boolean flag;
while (true) {
System.out.println("请输入一个数( 输入0退出):");
int a = object.nextInt();
if (a == 0) {
break;
}
else {
flag = false;
for (int i = a / 2; i > 1; i--) {
if (a % i == 0) {
flag = true;
System.out.println(a + "不是质数。");
break;
}
}
if(!flag)
System.out.println(a + "是质数。");
}
}
}
}求数组最大值(略)
计算数组平方和(略)
七大经典排序算法
- 冒泡排序(js写过,不太难,略)
1.23 Scanner类应用
从键盘获取不同类型的变量:需要使用Scanner类。
实现步骤:
- 导包:
import java.util.Scanner - Scanner实例化:
Scanner scan = new Scanner(System in); - 调用Scanner类的相关方法(next() / nextXxx()),来获取指定类型的变量。
注意: 需要根据相应的方法,来输入指定类型的值。如果输入的数据类型与要求的类型不匹配时,会报异常:
InputMisMatchException导致程序终止
1 | |
第二章 面向对象
第三章 异常处理
throw与throws的区别:
- throw:生成一个异常对象,并抛出,使用在方法内部<->自动抛出异常对象。
- throws:处理异常的方式使用在方法声明处的末尾<–>
try...catch...finally。
第四章 多线程
第五章 java常用类
5.1 字符串相关类
String特性
String类:代表字符串。Java程序中所有字符串字面值(如:”abc”)为此类的实例实现。
String是一个final类,代表不可变的字符序列,不能被继承。
1
2
3
4
5
6
7public final class String
implements java.io.Serializable, Comparable<String>, CharSequence{
// The value is used for character storage.
private final char value[];
private int hash; // Default 0
}String对象的字符内容是存储在一个字符数组value[]中的。
内存:

String对象的创建以及存储方式
1 | |

所以要分清楚到底是在常量池中,还是在堆空间中即可。




答案:True,画图分析
1 | |
字符串拼接

结论:
常量与常量的拼接结果在常量池。且常量池中不会存在相同内容的常量。
只要其中有一个是变量,结果就在堆中
如果拼接的结果调用intern()方法,返回值就在常量池中
1
String s8 = (s1 + s2).intern();1
2final String s = "Asuka";
String s1 = s + "Ayanami"; // 存储在常量池中,因为都是常量
JVM中涉及字符串的内存结构
一般用Hot Spot。
一个JVM实例只存在一个堆内存,堆内存的大小是可以调节的。类加载器读取了类文件后,需要把类、方法、常变量放到堆内存中,保存所有引用类型的真实信息,以便执行器执行,堆内存分为:
- 新生区
- 养老区
- 永久存储区(方法区): 被加载进此区域的数据是不会被垃圾回收器回收掉的,关闭JVM才会释放1此区域所占用的内存。但是一般不认为永久存储区堆的一部分。
- JDK8中字符串常量池在方法区中。
常用API
int length():返回字符串的长度:return value.lengthchar charAt(int index): 返回某索引处的字符return value[index]boolean isEmpty():判断是否是空字符串:return value.length == 0String toLowerCase():使用默认语言环境,将 String 中的所有字符转换为小写String toUpperCase():使用默认语言环境,将 String 中的所有字符转换为大写String trim():返回字符串的副本,忽略前导空白和尾部空白boolean equals(Object obj):比较字符串的内容是否相同boolean equalsIgnoreCase(String anotherString):与equals方法类似,忽略大 小写String concat(String str):将指定字符串连接到此字符串的结尾。 等价于用“+”结果赋值给变量后,返回值会被保存在
int compareTo(String anotherString):比较两个字符串的大小String substring(int beginIndex):返回一个新的字符串,它是此字符串的从 beginIndex开始截取到最后的一个子字符串。String substring(int beginIndex, int endIndex):返回一个新字符串,它是此字 符串从beginIndex开始截取到endIndex(不包含)的一个子字符串。boolean endsWith(String suffix):测试此字符串是否以指定的后缀结束boolean startsWith(String prefix):测试此字符串是否以指定的前缀开始boolean startsWith(String prefix, int toffset):测试此字符串从指定索引开始的 子字符串是否以指定前缀开始boolean contains(CharSequence s):当且仅当此字符串包含指定的 char 值序列 时,返回 trueint indexOf(String str):返回指定子字符串在此字符串中第一次出现处的索引int indexOf(String str, int fromIndex):返回指定子字符串在此字符串中第一次出 现处的索引,从指定的索引开始int lastIndexOf(String str):返回指定子字符串在此字符串中最右边出现处的索引int lastIndexOf(String str, int fromIndex):返回指定子字符串在此字符串中最后 一次出现处的索引,从指定的索引开始反向搜索 注:indexOf和lastIndexOf方法如果未找到都是返回-1String replace(char oldChar, char newChar):返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的。String replace(CharSequence target, CharSequence replacement):使用指定的字面值替换序列替换此字符串所有匹配字面值目标序列的子字符串。String replaceAll(String regex, String replacement): 使 用 给 定 的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。String replaceFirst(String regex, String replacement): 使 用 给 定 的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串。boolean matches(String regex):告知此字符串是否匹配给定的正则表达式。String[] split(String regex):根据给定正则表达式的匹配拆分此字符串。String[] split(String regex, int limit):根据匹配给定的正则表达式来拆分此 字符串,最多不超过limit个,如果超过了,剩下的全部都放到最后一个元素中。
String类型转换
String与基本数据类、包装类
字符串
-->基本数据类型、包装类调用包装类的静态方法:
包装类型.parseXxx(str)基本数据类型、包装类
-->字符串调用String的重载的
String.valueOf(xxx)方法
String与字符串数组转换
字符数组
-->字符串String 类的构造器:
String(char[])和String(char[],int offset,int length)分别用字符数组中的全部字符和部分字符创建字符串对象。字符串
-->字符数组public char[] toCharArray():将字符串中的全部字符存放在一个字符数组中的方法。public void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin):提供了将指定索引范围内的字符串存放到数组中的方法。
字符串与字节数组转换
字节数组
-->字符串:解码String(byte[]):通过使用平台的默认字符集解码指定的 byte 数组,构 造一个新的 String。String(byte[],int offset,int length):用指定的字节数组的一部分, 即从数组起始位置offset开始取length个字节构造一个字符串对象。字符串
-->字节数组:编码public byte[] getBytes():使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。public byte[] getBytes(String charsetName):使用指定的字符集将 此 String 编码到 byte 序列,并将结果存储到新的 byte 数组。
UTF-8中一个汉字占用三个字节。
GBK中一个汉字占用两个字节。
乱码:编码方式和解码方式不同。
StringBuffer类
java.lang.StringBuffer代表可变的字符序列,JDK1.0中声明,可以对字符 串内容进行增删,此时不会产生新的对象。- 很多方法与String相同。
- 作为参数传递时,方法内部可以改变值。
1 | |
StringBuffer类不同于String,其对象必须使用构造器生成。
有三个构造器:
- StringBuffer():初始容量为16的字符串缓冲区
- StringBuffer(int size):构造指定容量的字符串缓冲区
- StringBuffer(String str):将内容初始化为指定字符串内容

空参构造初始化容量

字符串参数构造初始化容量

底层扩容,扩容后如果不够,就直接把总长度作为新容量


length返回机制
常用方法:
StringBuffer append(xxx):提供了很多的append()方法,用于进行字符串拼接StringBuffer delete(int start,int end):删除指定位置的内容StringBuffer replace(int start, int end, String str):把[start,end)位置替换为strStringBuffer insert(int offset, xxx):在指定位置插入xxxStringBuffer reverse():把当前字符序列逆转- 如上这些方法支持方法链操作,方法链的原理:

例如:
a.append('').append('').delete(1,2).insert(3,'A')public int indexOf(String str)public String substring(int start,int end)public int length()public char charAt(int n )public void setCharAt(int n ,char ch)
StringBuilder类
StringBuilder 和 StringBuffer 非常类似,均代表可变的字符序列,而且 提供相关功能的方法也一样。

空参构造初始化容量

字符串参数构造初始化容量

底层扩容
- String、StringBuilder、StringBuffer三者之间的区别?
答:
String:不可变的字符序列。
StringBuffer:可变的字符序列;线程安全的,效率低。
StringBuilder:可变的字符序列,JDK5.0新增;线程不安全,效率高。
三者底层都是使用char[]存储。
效率:StringBuilder > StringBuffer > Stirng
源码分析
1
2
3String str = new String(); // value = new char[0];
String str1 = new String("abc"); // value = new char[]{'a', 'b', 'c'}需要频繁修改字符序列,就不要用String,考虑StringBuffer和StringBuffer
开发中,尽量用
1
2
3
4
5public synchronized void ensureCapacity(int minimumCapacity) {
if (minimumCapacity > value.length) {
expandCapacity(minimumCapacity);
}
}构造器先初始化容量,避免扩容的巨大开销。
5.2 JDK 8之前的日期时间API

java.lang.System类
System类提供的public static long currentTimeMillis()用来返回当前时 间与1970年1月1日0时0分0秒之间以毫秒为单位的时间差。
此方法适于计算时间差。
计算世界时间的主要标准有:
UTC(Coordinated Universal Time)
GMT(Greenwich Mean Time)
CST(Central Standard Time
java.util.Date类
表示特定的瞬间,精确到毫秒。
构造器:
Date():使用无参构造器创建的对象可以获取本地时间。Date(long date)
常用方法:
getTime():返回1970 年 1 月 1 日 00:00:00 GMT 以来此 Date 对象 表示的毫秒数。toString():把此 Date 对象转换为以下形式的 String: dow mon dd hh:mm:ss zzz yyyy 其中: dow 是一周中的某一天 (Sun, Mon, Tue, Wed, Thu, Fri, Sat),zzz是时间标准。其他很多方法已经过时
java.sql.Date:对应数据库中的日期类型的变量,跟数据库交互时使用。
ublic class Date extends java.util.Date
1 | |
两种Date类型相互转换,不能直接强制类型转换,因为子类强转为父类是不能赋值给一个父类变量的
1 | |
java.text.SimpleDateFormat类
- Date类的API不易于国际化,大部分被废弃了。
java.text.SimpleDateFormat类是一个不与语言环境有关的方式来格式化和解析日期的具体类。 - 它允许进行格式化:日期
-->文本;解析:文本-->日期 - 格式化:
SimpleDateFormat():默认的模式和语言环境创建对象public SimpleDateFormat(String pattern):该构造方法可以用参数pattern 指定的格式创建一个对象,该对象调用:public String format(Date date):方法格式化时间对象date
- 解析:
public Date parse(String source):从给定字符串的开始解析文本,以生成 一个日期。
1 | |
java.util.Calender(日历)类
Calendar是一个抽象基类,主要用于完成日期字段之间相互操作的功能。
获取Calendar实例的方法
- 使用
Calendar.getInstance()方法 - 调用它的子类
GregorianCalendar的构造器
- 使用
一个Calendar的实例是系统时间的抽象表示,通过
get(int field)方法来取得想要的时间信息。比如:YEAR、MONTH、DAY_OF_WEEK、HOUR_OF_DAY、MINUTE、SECONDpublic void set(int field, int value)public void add(int field, int amount)puclic final Date getTime()public final void setTime(Date date)
注意:
- 获取月份时:一月是0,二月是1,以此类推,12月是11
- 获取星期时:周日是1,周二是2……周六是7
1 | |
5.3 JDK 8中新日期时间API
新API出现背景:
- 可变性:像日期和时间这样的类应该是不可变的
- 偏移性:Date中的年份是从1900年开始的,而月份都从0开始
- 格式化:格式化只对Date有用,Calendar则不行
新时间API:
java.time:包含值对象的基础包java.time.chrono:提供对不同的日历系统的访问java.time.format:格式化和解析时间和日期java.time.temporal:包括底层框架和扩展特性java.time.zone:包含时区支持的类
说明:大多数开发者只会用到基础包和format包,也可能会用到temporal包。因此,尽 管有68个新的公开类型,大多数开发者,大概将只会用到其中的三分之一。
LocalDate、LocalTime、LocalDateTime
LocalDate、LocalTime、LocalDateTime类是其中较为重要的几个类,它们的实例都是不可变对象,分别表示使用 ISO-8601日历系统的日期、时间、日期和时间。 它们提供了简单的本地日期或时间,并不包含当前的时间信息,也不包含与时区 相关的信息。LocalDate代表IOS格式(yyyy-MM-dd)的日期,可以存储生日、纪念日等日期。LocalTime表示一个时间,而不是日期。LocalDateTime是用来表示日期和时间的,这是一个最常用的类之一。ISO-8601日历系统是国际标准化组织制定的现代公民的日期和时间的表示 法,也就是公历。
- 实例化
- 获取日期
- 修改日期
1 | |
瞬时:Instant
- Instant:时间线上的一个瞬时点。 这可能被用来记录应用程序中的事件时间戳。
- 在处理时间和日期的时候,我们通常会想到年,月,日,时,分,秒。然而,这只是时间的一个模型,是面向人类的。第二种通用模型是面向机器的,或者说是连 续的。在此模型中,时间线中的一个点表示为一个很大的数,这有利于计算机 处理。在UNIX中,这个数从1970年开始,以秒为的单位;同样的,在Java中, 也是从1970年开始,但以毫秒为单位。
java.time包通过值类型Instant提供机器视图,不提供处理人类意义上的时间 单位。Instant表示时间线上的一点,而不需要任何上下文信息,例如,时区。 概念上讲,它只是简单的表示自1970年1月1日0时0分0秒(UTC)开始的秒 数。因为java.time包是基于纳秒计算的,所以Instant的精度可以达到纳秒级。- (1 ns = 10-9 s) 1秒 = 1000毫秒 =10^6微秒=10^9纳秒
1 | |
格式化与解析日期或时间
java.time.format.DateTimeFormatter类:该类提供了三种格式化方法:
- 预定义的标准格式。如:
ISO_LOCAL_DATE_TIME;ISO_LOCAL_DATE;ISO_LOCAL_TIME - 本地化相关的格式。如:
ofLocalizedDateTime(FormatStyle.LONG) - 自定义的格式。如:
ofPattern(“yyyy-MM-dd hh:mm:ss”)
用的时候一般自定义。

1 | |
其他API
ZoneId:该类中包含了所有的时区信息,一个时区的ID,如Europe/ParisZonedDateTime:一个在ISO-8601日历系统时区的日期时间,如 2007-12- 03T10:15:30+01:00 Europe/Paris。- 其中每个时区都对应着ID,地区ID都为“{区域}/{城市}”的格式,例如:Asia/Shanghai等
Clock:使用时区提供对当前即时、日期和时间的访问的时钟。- 持续时间:
Duration,用于计算两个“时间”间隔 - 日期间隔:
Period,用于计算两个“日期”间隔。 TemporalAdjuster: 时间校正器。有时我们可能需要获取例如:将日期调整到“下一个工作日”等操作。TemporalAdjusters: 该类通过静态方法(firstDayOfXxx()/lastDayOfXxx()/nextXxx())提供了大量的常用TemporalAdjuster的实现。
1 | |
参考:与传统日期处理的转换

5.4 Java比较器
对象数组的排序问题,就涉及到对象之间的比较问题。
对象排序方式:
- 自然排序:
java.lang.Comparable - 定制排序:
java.util.Comparator
Comparable接口
Comparable接口强行对实现它的每个类的对象进行整体排序。这种排序被称 为类的自然排序。- 实现
Comparable的类必须实现compareTo(Object obj)方法,两个对象即通过compareTo(Object obj)方法的返回值来比较大小。如果当前对象this大于形参对象obj,则返回正整数,如果当前对象this小于形参对象obj,则返回负整数,如果当前对象this等于形参对象obj,则返回零。 - 实现
Comparable接口的对象列表(和数组)可以通过Collections.sort或Arrays.sort进行自动排序。实现此接口的对象可以用作有序映射中的键或有 序集合中的元素,无需指定比较器。 - 对于类 C 的每一个 e1 和 e2 来说,当且仅当
e1.compareTo(e2) == 0与e1.equals(e2)具有相同的boolean值时,类 C 的自然排序才叫做与 equals一致。建议(虽然不是必需的)最好使自然排序与equals一致。 - 对于自定义类,如果需要排序,我们可以自定义类实现
Comparable接口,重写Comparable(obj)方法,在方法中指明如何排序。
案例:Comparable 的典型实现:(默认都是从小到大排列的)
- String:按照字符串中字符的Unicode值进行比较
- Character:按照字符的Unicode值来进行比较
- 数值类型对应的包装类以及BigInteger、BigDecimal:按照它们对应的数值 大小进行比较
- Boolean:true 对应的包装类实例大于 false 对应的包装类实例
- Date、Time等:后面的日期时间比前面的日期时间大
1 | |
Comparator接口
- 当元素的类型没有实现
java.lang.Comparable接口而又不方便修改代码, 或者实现了java.lang.Comparable接口的排序规则不适合当前的操作,那 么可以考虑使用Comparator的对象来排序,强行对多个对象进行整体排序的比较。 - 重写
compare(Object o1,Object o2)方法,比较o1和o2的大小:如果方法返 回正整数,则表示o1大于o2;如果返回0,表示相等;返回负整数,表示 o1小于o2。 - 可以将
Comparator传递给 sort 方法(如Collections.sort 或 Arrays.sort),从而允许在排序顺序上实现精确控制。 - 还可以使用
Comparator来控制某些数据结构(如有序 set或有序映射)的顺序,或者为那些没有自然顺序的对象collection提供排序。
5.5 System类
System类代表系统,系统级的很多属性和控制方法都放置在该类的内部。该类位于java.lang包。
由于该类的构造器是private的,所以无法创建该类的对象,也就是无法实 例化该类。其内部的成员变量和成员方法都是static的,所以也可以很方便 的进行调用。
成员变量
- System类内部包含in、out和err三个成员变量,分别代表标准输入流 (键盘输入),标准输出流(显示器)和标准错误输出流(显示器)。
成员方法
native long currentTimeMillis(): 该方法的作用是返回当前的计算机时间,时间的表达格式为当前计算机时间和GMT时间(格林威治时间)1970年1月1号0时0分0秒所差的毫秒数。void exit(int status): 该方法的作用是退出程序。其中status的值为0代表正常退出,非零代表异常退出。使用该方法可以在图形界面编程中实现程序的退出功能等。void gc(): 该方法的作用是请求系统进行垃圾回收。至于系统是否立刻回收,则取决于系统中垃圾回收算法的实现以及系统执行时的情况。String getProperty(String key): 该方法的作用是获得系统中属性名为key的属性对应的值。系统中常见 的属性名以及属性的作用如下表所示:
5.6 Math类

5.7 BigInteger与BigDecimal
BigInteger
Integer类作为int的包装类,能存储的最大整型值为2^31-1,Long类也是有限的, 最大为2^63-1。如果要表示再大的整数,不管是基本数据类型还是他们的包装类 都无能为力,更不用说进行运算了。
java.math包的
BigInteger可以表示不可变的任意精度的整数。BigInteger 提供所有 Java 的基本整数操作符的对应物,并提供java.lang.Math的所有相关方法。 另外,BigInteger还提供以下运算:模算术、GCD 计算、质数测试、素数生成、 位操作以及一些其他操作。构造器
BigInteger(String val):根据字符串构建BigInteger对象
常用方法
public BigInteger abs():返回此 BigInteger 的绝对值的 BigInteger。BigInteger add(BigInteger val):返回其值为(this + val)的 BigIntegerBigInteger subtract(BigInteger val):返回其值为(this - val)的 BigIntegerBigInteger multiply(BigInteger val):返回其值为(this * val)的 BigIntegerBigInteger divide(BigInteger val):返回其值为(this / val)的 BigInteger。整数 相除只保留整数部分。BigInteger remainder(BigInteger val):返回其值为(this % val)的 BigInteger。BigInteger[] divideAndRemainder(BigInteger val):返回包含(this / val)后跟(this % val)的两个 BigInteger 的数组。BigInteger pow(int exponent):返回其值为(this^exponent)的 BigInteger。
BigDecimal
- 一般的Float类和Double类可以用来做科学计算或工程计算,但在商业计算中, 要求数字精度比较高,故用到java.math.BigDecimal类。
- BigDecimal类支持不可变的、任意精度的有符号十进制定点数。
- 构造器
- public BigDecimal(double val)
- public BigDecimal(String val)
- 常用方法
public BigDecimal add(BigDecimal augend)public BigDecimal subtract(BigDecimal subtrahend)public BigDecimal multiply(BigDecimal multiplicand)public BigDecimal divide(BigDecimal divisor, int scale, int roundingMode)
1 | |
第七章 枚举类&注解
7.1 枚举类的使用
类的对象只有有限个,确定的。
当需要定义一组常量时,强烈建议使用枚举类。
枚举类的实现:
- JDK1.5 之前需要自定义枚举类
- JDK1.5新增的enum关键字用于定义枚举类
若枚举只有一个对象, 则可以作为一种单例模式的实现方式。
枚举类的属性
- 枚举类对象的属性不应允许被改动, 所以应该使用
private final修饰 - 枚举类的使用
private final修饰的属性应该在构造器中为其赋值 - 若枚举类显示的定义了带参数的构造器,则在列出枚举值时也必须对应的传入参数。
- 枚举类对象的属性不应允许被改动, 所以应该使用
自定义枚举类:
- 私有化类的构造器,保证不能在类的外部创建其对象
- 在类的内部创建枚举类的实例。声明为:
public static final - 对象如果有实例变量,应该声明为
private final,并在构造器中初始化。
1 | |
- 使用enum定义枚举类
- 使用 enum 定义的枚举类默认继承了
java.lang.Enum类,因此不能再继承其他类。 - 枚举类的构造器只能使用
private权限修饰符。 - 枚举类的所有实例必须在枚举类中显式列出(, 分隔 ; 结尾)。列出的 实例系统会自动添加
public static final修饰
- 使用 enum 定义的枚举类默认继承了
1 | |
Enum类的主要方法:
values()方法:返回枚举类型的对象数组。该方法可以很方便地遍历所有的枚举值valueOf(String str):可以把一个字符串转为对应的枚举类对象。要求字符 串必须是枚举类对象的“名字”。如不是,会有运行时异常:IllegalArgumentExceptiontoString():返回当前枚举类对象常量的名称
Enum枚举类实现接口:
- 和普通 Java 类一样,枚举类可以实现一个或多个接口。
- 若每个枚举值在调用实现的接口方法呈现相同的行为方式,则只要统一实现该方法即可。
- 若需要每个枚举值在调用实现的接口方法呈现出不同的行为方式, 则可以让每个枚举值分别来实现该方法。
1 | |
switch遍历类型:byte / short / char / int / String / 枚举类对象
7.2 注解(Annotation)
7.2.1 注解概述
从 JDK 5.0 开始, Java 增加了对元数据(MetaData) 的支持, 也就是
Annotation(注解)Annotation其实就是代码里的特殊标记, 这些标记可以在编译, 类加载, 运行时被读取, 并执行相应的处理。通过使用Annotation, 程序员 可以在不改变原有逻辑的情况下, 在源文件中嵌入一些补充信息。代码分析工具、开发工具和部署工具可以通过这些补充信息进行验证或者进行部署。Annotation 可以像修饰符一样被使用, 可用于修饰包,类, 构造器, 方法, 成员变量, 参数, 局部变量的声明, 这些信息被保存在
Annotation的“name=value”对中。在JavaSE中,注解的使用目的比较简单,例如标记过时的功能, 忽略警告等。在JavaEE/Android中注解占据了更重要的角色,例如 用来配置应用程序的任何切面,代替JavaEE旧版中所遗留的繁冗代码和XML配置等。
未来的开发模式都是基于注解的,JPA是基于注解的,Spring2.5以上都是基于注解的,Hibernate3.x以后也是基于注解的,现在的 Struts2有一部分也是基于注解的了,注解是一种趋势,一定程度上可以说:
框架 = 注解 + 反射 + 设计模式。
7.2.2 常见Annotation示例
使用 Annotation 时要在其前面增加 @ 符号, 并把该 Annotation 当成 一个修饰符使用。用于修饰它支持的程序元素。
示例一:生成文档相关的注解
- @author 标明开发该类模块的作者,多个作者之间使用,分割
- @version 标明该类模块的版本
- @see 参考转向,也就是相关主题
- @since 从哪个版本开始增加的
- @param 对方法中某参数的说明,如果没有参数就不能写
- @return 对方法返回值的说明,如果方法的返回值类型是void就不能写
- @exception 对方法可能抛出的异常进行说明 ,如果方法没有用throws显式抛出的异常就不能写 其中
- @param @return 和 @exception 这三个标记都是只用于方法的。
- @param的格式要求:@param 形参名 形参类型 形参说明
- @return 的格式要求:@return 返回值类型 返回值说明
- @exception的格式要求:@exception 异常类型 异常说明
- @param和@exception可以并列多个
示例二:在编译时进行格式检查(JDK内置的三个基本注解)
@Override: 限定重写父类方法, 该注解只能用于方法@Deprecated: 用于表示所修饰的元素(类, 方法等)已过时。通常是因为所修饰的结构危险或存在更好的选择,抑制多个警告,传递一个数组:@SuppressWarinings({"unused", "rawtypes"})@SuppressWarnings: 抑制编译器警告
示例三:跟踪代码依赖性,实现替代配置文件功能
Servlet3.0提供了注解(annotation),使得不再需要在web.xml文件中进行Servlet的部署。
spring框架中关于“事务”的管理

7.2.3 自定义注解
- 定义新的 Annotation 类型使用 @interface关键字
- 自定义注解自动继承了
java.lang.annotation.Annotation接口 Annotation的成员变量在 Annotation 定义中以无参数方法的形式来声明。其方法名和返回值定义了该成员的名字和类型。我们称为配置参数。类型只能是八种基本数据类型、String类型、Class类型、enum类型、Annotation类型、 以上所有类型的数组。- 可以在定义 Annotation 的成员变量时为其指定初始值, 指定成员变量的初始 值可使用 default 关键字
- 如果只有一个参数成员,建议使用参数名为value
- 如果定义的注解含有配置参数,那么使用时必须指定参数值,除非它有默认 值。格式是“参数名 = 参数值” ,如果只有一个参数成员,且名称为value, 可以省略
“value=” - 没有成员定义的 Annotation 称为标记;包含成员变量的 Annotation 称为元数 据 Annotation
注意:自定义注解必须配上注解的信息处理流程(反射)才有意义。
7.2.4 元注解
JDK 的元 Annotation 用于修饰其他 Annotation 定义
JDK5.0提供了4个标准的meta-annotation类型,分别是:
- Retention
- Target
- Documented
- Inherited
元数据的理解: String name = “atguigu”;
@Retention: 只能用于修饰一个 Annotation 定义, 用于指定该 Annotation 的生命周期,@Rentention包含一个RetentionPolicy类型的成员变量, 使用@Rentention时必须为该 value 成员变量指定值:RetentionPolicy.SOURCE:在源文件中有效(即源文件保留),编译器直接丢弃这种策略的注释RetentionPolicy.CLASS:在class文件中有效(即class保留),当运行 Java 程序时, JVM 不会保留注解。 这是默认值。RetentionPolicy.RUNTIME:在运行时有效(即运行时保留),当运行 Java 程序时, JVM 会保留注释。程序可以通过反射获取该注释。
1
2
3
4
5
6
7
8
9
10public enum RetentionPolicy{
SOURCE,
CLASS,
RUNTIME
}
@Retention(RetentionPolicy.SOURCE)
@interface MyAnnotation1{ }
@Retention(RetentionPolicy.RUNTIME)
@interface MyAnnotation2{ }@Target: 用于修饰 Annotation 定义, 用于指定被修饰的 Annotation 能用于修饰哪些程序元素。@Target也包含一个名为 value 的成员变量。1
2
3
4
5
6
7
8
9
10
11
12public enum ElementType {
TYPE,
FIELD,
METHOD,
PARAMETER,
CONSTRUCTOR,
LOCAL_VARIABLE,
ANNOTATION_TYPE,
PACKAGE,
TYPE_PARAMETER,
TYPE_USE
}
@Documented: 用于指定被该元 Annotation 修饰的 Annotation 类将被 javadoc 工具提取成文档。默认情况下,javadoc是不包括注解的。- 定义为
Documented的注解必须设置Retention值为RUNTIME。
- 定义为
@Inherited: 被它修饰的 Annotation 将具有继承性。如果某个类使用了被@Inherited修饰的 Annotation, 则其子类将自动具有该注解。- 比如:如果把标有
@Inherited注解的自定义的注解标注在类级别上,子类则可以继承父类类级别的注解 - 实际应用中,使用较少
- 通过反射获取注解信息:
Annotation[] annotations = Student.class.getAnnotation;
- 比如:如果把标有
7.2.5 反射获取注解信息
JDK 5.0 在
java.lang.reflect包下新增了AnnotatedElement接口, 该接口代表程序中可以接受注解的程序元素。当一个 Annotation 类型被定义为运行时 Annotation 后, 该注解才是运行时可见, 当 class 文件被载入时保存在 class 文件中的 Annotation 才会被虚拟机读取
程序可以调用 AnnotatedElement对象的如下方法来访问 Annotation 信息:
getAnnotation(Class<T> annotationClass)getAnnotations()getDeclaredAnnotations()isAnnotationPresent(Class <? extends Annotation> annotationClass)
7.2.6 JDK8注解新特性
Java 8对注解处理提供了两点改进:可重复的注解及可用于类型的注解。此外, 反射也得到了加强,在Java8中能够得到方法参数的名称。这会简化标注在方法参数上的注解。
jdk8之前:声明一个成员变量为要重复的注解的数组。

- 在MyAnnotation上声明
@repeatable,成员值为Annotations.class- MyAnnotation的Target和Rentation和MyAnnotations相同
类型注解:
- JDK1.8之后,关于元注解
@Target的参数类型ElementType枚举值多了两个: TYPE_PARAMETER,TYPE_USE。 - 在Java 8之前,注解只能是在声明的地方所使用,Java8开始,注解可以应用在任何地方。
ElementType.TYPE_PARAMETER表示该注解能写在类型变量的声明语句中(如:泛型声明)。ElementType.TYPE_USE表示该注解能写在使用类型的任何语句中。
1 | |
1 | |
第八章 java集合
8.1 概述
一方面, 面向对象语言对事物的体现都是以对象的形式,为了方便对多个对象 的操作,就要对对象进行存储。另一方面,使用Array存储(内存层面,不涉及持久化)对象方面具有一些弊 端,而Java 集合就像一种容器,可以动态地把多个对象的引用放入容器中。
- 数组在内存存储方面的特点:
- 数组初始化以后,长度就确定了。
- 数组声明的类型,就决定了进行元素初始化时的类型
- 数组在存储数据方面的弊端:
- 数组初始化以后,长度就不可变了,不便于扩展
- 数组中提供的属性和方法少,不便于进行添加、删除、插入等操作,且效率不高。 同时无法直接获取存储元素的个数(.length只是数组长度,不是放了多少个元素进去)
- 数组存储的数据是有序的、可以重复的。—->存储数据的特点单一
- Java 集合类可以用于存储数量不等的多个对象,还可用于保存具有映射关系的关联数组
使用场景:

Java 集合可分为 Collection 和 Map 两种体系:
- Collection接口:单列数据,定义了存取一组对象的方法的集合
- List:元素有序、可重复的集合–>动态数组
- Set:元素无序、不可重复的集合
- Map接口:双列数据,保存具有映射关系“key-value对”的集合

集合API位于java.util包内。

8.2 Collection接口
概述:
Collection 接口是 List、Set 和 Queue 接口的父接口,该接口里定义的方法既可用于操作 Set 集合,也可用于操作 List 和 Queue 集合。
JDK不提供此接口的任何直接实现,而是提供更具体的子接口(如:Set和List) 实现。
在 JDK 5 之前,Java 集合会丢失容器中所有对象的数据类型,把所有对象都当成 Object 类型处理;从 JDK 5.0 增加了泛型以后,Java 集合可以记住容器中对象的数据类型。
Collection接口方法:
- 添加:
- add(Object obj)
- addAll(Collection coll)
- 获取有效元素的个数:int size()
- 清空集合:void clear()
- 是否是空集合:boolean isEmpty()
- 是否包含某个元素:
- boolean contains(Object obj):是通过元素的equals方法来判断是否 是同一个对象
- boolean containsAll(Collection c):也是调用元素的equals方法来比 较的。拿两个集合的元素挨个比较。
- 删除
- boolean remove(Object obj) :通过元素的equals方法判断是否是要删除的那个元素。只会删除找到的第一个元素
- boolean removeAll(Collection coll):取当前集合的差集
- 取两个集合的交集:
- boolean retainAll(Collection c):把交集的结果存在当前集合中,不影响c
- 集合是否相等:boolean equals(Object obj)
- 转成对象数组:Object[] toArray()
- 获取集合对象的哈希值hashCode()
- 遍历
- iterator():返回迭代器对象,用于集合遍历
1 | |
8.3 Iterator迭代器接口
- Iterator对象称为迭代器(设计模式的一种),主要用于遍历 Collection 集合中的元素。
- GOF给迭代器模式的定义为:提供一种方法访问一个容器(container)对象中各个元 素,而又不需暴露该对象的内部细节。迭代器模式,就是为容器而生。类似于“公交车上的售票员”、“火车上的乘务员”、“空姐”。
- Collection接口继承了
java.lang.Iterable接口,该接口有一个iterator()方法,那么所有实现了Collection接口的集合类都有一个iterator()方法,用以返回一个实现了 Iterator接口的对象。 - Iterator 仅用于遍历集合,Iterator 本身并不提供承装对象的能力。如果需要创建 Iterator 对象,则必须有一个被迭代的集合。
- 集合对象每次调用
iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
方法:
hasNext():如果迭代对象还有元素没有遍历到,返回true。在调用
it.next()方法之前必须要调用it.hasNext()进行检测。若不调用,且下一条记录无效,直接调用it.next()会抛出NoSuchElementException异常。next():返回下一次迭代遍历到的元素。remove():从基础集合中移除此迭代器返回的最后一个元素(可选操作)。每次调用next时只能调用此方法一次。- 注意:
Iterator可以删除集合的元素,但是是遍历过程中通过迭代器对象的remove方法,不是集合对象的remove方法。- 如果还未调用
next()或在上一次调用next方法之后已经调用了remove方法, 再调用remove都会报IllegalStateException。
- 注意:

1 | |
使用
foreach循环遍历集合元素Java 5.0 提供了 foreach 循环迭代访问 Collection和数组。
遍历操作不需获取Collection或数组的长度,无需使用索引访问元素。
遍历集合的底层调用Iterator完成操作。
foreach还可以用来遍历数组。
foreach中不要用remove删除集合元素,因为这里的remove调用的会是集合的remove,而不是iterator的remove
- 如果要进行remove操作,可以调用迭代器的 remove 方法而不是集合类的 remove 方法。因为如果列表在任何时间从结构上修改创建迭代器之后,以任何方式除非通过迭代器自身remove/add方法,迭代器都将抛出一个
ConcurrentModificationException,这就是单线程状态下产生的 fail-fast 机制。
- 如果要进行remove操作,可以调用迭代器的 remove 方法而不是集合类的 remove 方法。因为如果列表在任何时间从结构上修改创建迭代器之后,以任何方式除非通过迭代器自身remove/add方法,迭代器都将抛出一个
易错:
1
2
3
4
5
6
7
8String[] strArr = new String[]{"A", "B", "C"};
for(int index = 0;index<strArr.length;index++){
strArr[i] = "Y"; // 会改变原数组
}
for(String str:strArr){
str = "X"; // 无法改变原数组,因为值传递原则
}1
2
3
4
5String a = new String("A");
String x = a; // 直接指向常量池的值 + b
x = "CC";
System.out.println(a == x); // false
System.out.println(a); // A
8.4 Collection子接口之一:List接口
8.5 Collection子接口之二:Set接口
8.6 Map接口
8.7 Collections工具
第九章 泛型
第十章 IO流
第十一章 网络编程
第十二章 java反射机制
第十三章 java8新特性
第十四章 java9&java10&java11新特性
Redis
1 | |
JDBC
1 | |
数据库连接池,初始连接数,最大连接数,这样做是空间换时间,避免了反复创建、销毁连接的代价。
分页查询:
1 | |




TomCat
java编写的web容器,将web项目放到webapps目录下启动即可。
cmd日志乱码\bin\logging.properties
1 | |


http默认端口号80。
Tomcat中,.war包在webapps下会自动解压缩。








Servlet
Servlet执行流程
Servlet对象是由Tomcat web服务器创建的,service方法也是服务器调用的。
服务器为什么知道Servlet中一定有service方法?
因为我们自定义的Servlet,必须实现Servlet接口,并复写其方法,而Servlet接口中有service方法。
Servlet生命周期
加载和实例化:默认情况下,当Servlet第一词被访问时,由容器创建Servlet对象。
@WebServlet(urlPatterns = "/demo", loadOnStartUp = 1)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
负整数:第一次被访问时创建Servlet对象
0或正整数:服务器启动时创建Servlet对象,数字越小,优先级越高。
* 初始化:在Servlet实例化后,容器将调用Servlet的init()方法初始化这个对象,完成一些如加载配置文件、创建连接等初始化工作。**该方法只调用一次。**
* 请求和处理:每次请求Servlet时,Servlet容器都会调用Servlet实例的service()方法对请求进行处理。
* 服务终止:在destroy方法调用后,容器会调用Servlet实例的destory方法完成资源的释放。在destroy()方法调用之后,容器会释放这个Servlet实例,该实例随后会被Java垃圾回收器所回收。
## Servlet方法简介
* init()
* service()
* destroy()
* getServletInfo()
* getServletConfig()
* ```java
private ServletConfig config;
public void init(ServletConfig config) throws ServletException{
this.config = config;
System.out.println("init()……");
}
public ServletConfig getServletConfig(){
return config;
}

Servlet体系结构
引入:实现Servlet接口,需要复写5个方法,很麻烦。


urlPattern配置


当一个路径同时满足精确匹配和目录匹配,那么精确匹配的优先级高于目录匹配。
/*的优先级高于/
千万不要/*.do,这样是错误的。

所以不要去配置/和/*,以免访问不了静态资源。
- 优先级:精确路径 -> 目录路径 -> 扩展名路径 ->
/*->/
xml配置方式编写Servlet

Request
获取请求数据



字符输入流:文本
字节输入流:文件 / 图片等
获取请求参数





doPost()中使用this.doGet()复用代码
请求参数中文乱码

一个汉字3个字节

cmd -> calc使用计算器

乱码原因:tomcat进行url解码,默认字符集为ISO-8859-1
解决方法:大致就是先编码,将数据转换为字节数组,然后解码。

简化:
1 | |
这种方法GET和POST请求方法通用。

请求转发

Response

设置响应数据功能介绍

重定向


资源路径问题


响应字符数据


响应字节数据



使用工具类读取流。
Servlet编写优化



会话跟踪技术
请求间共享数据,用户身份认证。
cookie



对于cookie不能存储中文:
1 | |
session
数据存储在客户端并不是很安全,会被篡改,会被截获。

session是基于cookie实现的,每一次会话都有对应的session,不同的会话session不同,通过cookie识别服务器是否有对应的session。



登录注册

验证码生成使用CheckCodeUtil.java工具类

Filter



放行前对request数据进行处理,方向后对response数据进行处理


注解配置的Filter,优先级按照过滤器类名(字符串)的自然排序。

Listener


Maven基础
黑马
1 | |
生命周期:同一生命周期内,执行后边的命令,前面的所有命令也会自动执行。
clean
pre-clean -> clean -> post-clean
default:核心工作,例如编译、测试、打包、安装
compile -> test -> package -> install
site
pre-site -> site -> post-site
IDEA内置有内置maven,但是最好自己配置,因为默认C盘。
Maven左边
groupId:定义当前Maven项目隶属于组织名称(通常为域名反写)
artifactId:定义当前Maven项目名称(通常为模块名称)
version:定义当前项目版本号
1 | |
依赖管理中的scope配置项:生效范围,默认compiler
MyBatis
简单使用
优秀的持久层框架,用于简化JDBC开发。
持久层:负责将数据保存到数据库的那一层代码。
JavaEE三层架构:表现层(页面展示)、业务层(逻辑处理)、持久层(数据持久化)
Mybatis免除了几乎所有JBDC代码以及设置参数和获取结果集的工作。
MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
查询数据
- 创建表,添加数据
- 创建模块,导入坐标
- 编写Mybatis核心配置文件 -> 替换连接信息,解决硬编码问题
- 编写sql映射文件 -> 统一管理sql,解决硬编码问题
- 编码
- 定义POJO类
- 加载核心配置文件,获取SqlSessionFactory对象
- 获取SqlSession对象,执行SQL语句
- 释放资源
Mapper代理方式
- 定义与SQL映射文件同名的Mapper接口,并且将Mapper接口和SQL映射文件放置在同一目录下
- 设置SQL映射文件的namespace属性为Mapper接口全限定名。
- 在Mapper接口中定义方法,方法名就是SQL映射文件中sql语句的id,并保持参数类型和返回值类型一致。
注意:如果Mapper接口名称和SQL映射文件一致,并在同一目录下,则可以用包扫描的方式简化mybatis-config.xml中的SQL映射文件的加载。
1 | |
Myabtis核心配置文件
environments:配置数据库连接环境信息。可以配置多个environment,通过default属性切换不同的environment。
typeAliases:配置
注意:配置各个xml 标签时,需要遵循先后顺序。

1
2
3
4
5
6
7
8<typeAliases>
<typeAlias alias="Author" type="domain.blog.Author"/>
<typeAlias alias="Blog" type="domain.blog.Blog"/>
<typeAlias alias="Comment" type="domain.blog.Comment"/>
<typeAlias alias="Post" type="domain.blog.Post"/>
<typeAlias alias="Section" type="domain.blog.Section"/>
<typeAlias alias="Tag" type="domain.blog.Tag"/>
</typeAliases>1
2
3<typeAliases>
<package name="domain.blog"/>
</typeAliases>MybatisX插件
案例摘录
数据库表的字段名称和实体类的属性名称不一致时,则不能自动封装数据(数据库中column-stu_score,实体类:stuScore),解决:
起别名:在xml的sql中给stu_socre起别名
对不一样的列名起别名,让实体类和别名一致即可
1
select stu_score as stuScore from stu;但是每次都写别名会很麻烦,所以可以封装sql片段。
1
2
3
4
5
6
7
8
9<sql id="stu_column">
stu_score as stuScore
</sql>
<select id="selectAllFromStu" resultType="Stu">
select
<include refid="stu_column" />
from stu;
</select>但是不灵活
ResultMap
1
2
3
4
5
6
7
8
9
10
11
12
13
14<resultMap id="stuResultMap" type="stu">
<!--
resultMap的id属性:唯一标识
type:映射的类型,支持typeAlias别名
内部id标签:完成逐渐字段映射
内部result标签:完成一般字段映射
-->
<result column="stu_score" property="StuScore" />
</resultMap>
<select id="selectAllFromStu" resultMap="stuResultMap">
select * from stu;
</select>- 定义
<resultMap> - 在
<select>标签中,使用resultMap替换resultType属性
- 定义
参数占位符:
#{}:会将其替换为?,为了防止SQL注入${}:拼sql,会存在sql注入问题
特殊符号处理,例如
<在xml中表示标签开始。转义字符:
<CDATA区:
1
<![CDATA[ < ]]>
传参接口传参给sql:
@params("name") int name- 封装为object
- 封装为Map
动态sql
1
<if test=""></if>但是存在and问题,解决:
- 添加恒等式:
1 = 1,然后每个条件sql中都使用and(如果是or,用1 = 0) - mybatis中,使用
<where>替换where 关键字,包裹条件sql区域即可
- 添加恒等式:
单条件动态条件查询
使用
choose(when, otherwise),类似于switch语句
默认查询可以使用
1 = 1,或者使用where标签提交事务


插入数据后返回id

修改动态字段

使用set标签,规避掉可能的
,多余问题。批量删除

mybatis会将数组参数,封装为Map集合。
默认:array = 数组,这里就需要配置
collection = "array"或者使用
@Param注解来改变map集合的默认key名称千万不要不写注解直接写名称

separator属性用来设置可能需要的分隔符
open:开始时拼接符close:结束时拼接符MyBatis参数传递:paramNameResolver
多个参数:封装为Map集合
1
2
3
4map.put("arg0" , 参数值)
map.put("param0" , 参数值)
map.put("arg1" , 参数值)
map.put("param1" , 参数值)@param注解:替换Map集合中默认的arg键名。


参数传递的是Map,所以
username = ${user.getUsername}
提取工具类

而且反复创建
sqlSessionFactory是十分占用资源的,因为使用了数据库连接池,所以都会创建一个连接池。但是注意:不要把
SqlSession也封装了,因为它代表一个数据库连接,抽取后,所有功能都公用一个连接,这样很不合理,因为这样不能管理事务,而且会让多个用户、多个功能之间相互影响。
Spring
黑马SSM
1.spring简介
Spring:分层的JavaEE/SE应用全栈轻量级开源框架,以IoC(控制反转)和AOP(面向切面编程)为内核。
提供了展现层SpringMVC和持久层Spring JDBCTemplate以及业务层事务管理等众多的企业级应用技术,还能整合开源的众多第三方框架和类库,逐渐成为使用最多的Java EE 企业应用开发框架。
发展历程:略
Spring优势:
- 方便解耦,简化开发
- AOP编程支持
- 声明式事务的支持
- 方便测试
- 方便集成各种优秀框架
- 降低Java EE API使用难度
- java源码是经典学习案例
Spring体系结构

2.Spring快速入门
开发步骤:
SpringMVC

